来源于:
MIT-Introduction to Deep Learning
代码为MIT课程练习LAB,可以使用Colab进行学习。链接:
MIT-Codes Github resposibility
Information:
1 | # Copyright 2022 MIT 6.S191 Introduction to Deep Learning. All Rights Reserved. |
Lab 1: Intro to TensorFlow and Music Generation with RNNs
Part 1:Intro to TensorFlow
创建tf值
-
x=tf.constant('String', tf.string):
创建一个常量,这个常量可以是多维列表。
tf.string表示为字符串,tf.float64表示浮点型。 -
x=tf.Variable(value):创建一个变量 -
tf.zeros([a, b, c]):创建一个全是0的矩阵,列表中表示size。
查看tf变量属性
tf.rank(value).numpy():查看value的维数tf.shape(value).numpy():查看value的大小
tf计算函数
tf.add(a, b): a+btf.subtract(a, b): a-btf.multiply(a, b): a*b
创建一个简单的神经网络
使用的输出公式: y=sigmoid(xW+b)
1 | ### Defining a network Layer ### |
使用时序(Sequential)API的神经网络
1 | from tensorflow.keras import Sequential |
测试输出:
1 | x_input = tf.constant([[1,2.]], shape=(1,2)) |
使用Model类创建继承的子类SubclassModel:
1 | from tensorflow.keras import Model |
在call函数中增加:isidentity=False,
isidentity,“有时我们希望网络简单地输出原来的值”。
True时返回输入值,否则正常执行。
梯度计算
通过GradientTape()方法实现梯度计算。
1 | x = tf.Variable(3.0) |
SGD梯度法优化方法:
计算损失L=(x−x_f)^2
1 | x = tf.Variable([tf.random.normal([1])]) # x随机取值 |
Lab 2: Computer Vision
Part 1: MNIST Digit Classification 手写数字识别
初始模型创建
1 | def build_fc_model(): |
第一层全连接层使用relu激活函数,第二层全连接层用于输出预测的概率值,使用softmax激活函数.
这里使用tf.nn.relu形式,如果用'relu'会报错。
模型编译
在训练模型之前执行模型编译,包括设置优化器、损失函数、训练测试的指标:这里使用准确率。
1 | model.compile(optimizer=tf.keras.optimizers.SGD(learning_rate=1e-1), |
模型训练
训练过程中显示损失和准确率。
- epochs:训练次数
1 | BATCH_SIZE = 64 |
使用测试训练集测试模型准确性
evaluate方法用来测试准确性。
1 | test_loss, test_acc = model.evaluate(x=test_images, y=test_labels) |
创建CNN网络模型,并进行编译、训练和测试。
创建模型:
1 | def build_cnn_model(): |
编译:
1 | cnn_model.compile(optimizer=tf.keras.optimizers.Adam(learning_rate=1e-3), loss='sparse_categorical_crossentropy', metrics=['accuracy']) |
训练:
1 | cnn_model.fit(x=train_images, y=train_labels, batch_size=BATCH_SIZE, epochs=EPOCHS) |
测试:
1 | test_loss, test_acc = cnn_model.evaluate(train_images, train_labels) |
至此模型已经训练完毕,此时输入图片进行预测:
1 | predictions = cnn_model.predict(test_images) |
输出为:
1 | array([1.1896365e-08, 2.9328827e-08, 1.0020367e-07, 1.9016676e-07, |

使用随机梯度下降训练CNN网络模型
1 | # 重建CNN网络 |
Part 2: Debiasing Facial Detection Systems 去偏面部检测系统
依赖项:
1 | import tensorflow as tf |
获取数据集
获取数据的网站:
- Celeba: 脸部图像数据集,此处为正向数据。
- ImageNet:不同类别的图像集
- Fitzpatrick Scale:肤色分类系统
1 | # 从Celeba和ImageNet获取数据 |
定义并训练CNN网络模型
定义四层卷积层,然后输出
1 | n_filters = 12 # 卷积滤波器的base number |
对模型进行训练:
1 | # 训练使用的参数集 |
性能评估:
- 此部分使用CelebA数据集进行评估。
1 | # 标准CNN网络模型 |
- 使用未知数据集进行评估
1 | ### 评估在测试数据上的CNN网络模型 |
用于学习隐结构(latent structure)的变分自编码器(VAE)
对于某些训练集中不存在或者存在较少的特征,例如深色皮肤,戴帽子的人等,
这些特征可以通过无监督的学习方式,使用VAE进行训练。
1 | # 定义VAE损失函数 |
VAEs重参数计算;
1 | # 输入为:隐分布(潜在分布)均值、隐分布的log值 |
DB-VAE 去偏变分自编码器
将具有更低出现频率的特征增加采样,而高频特征减少采样,达到平均采样的目的。
具体流程图如下:
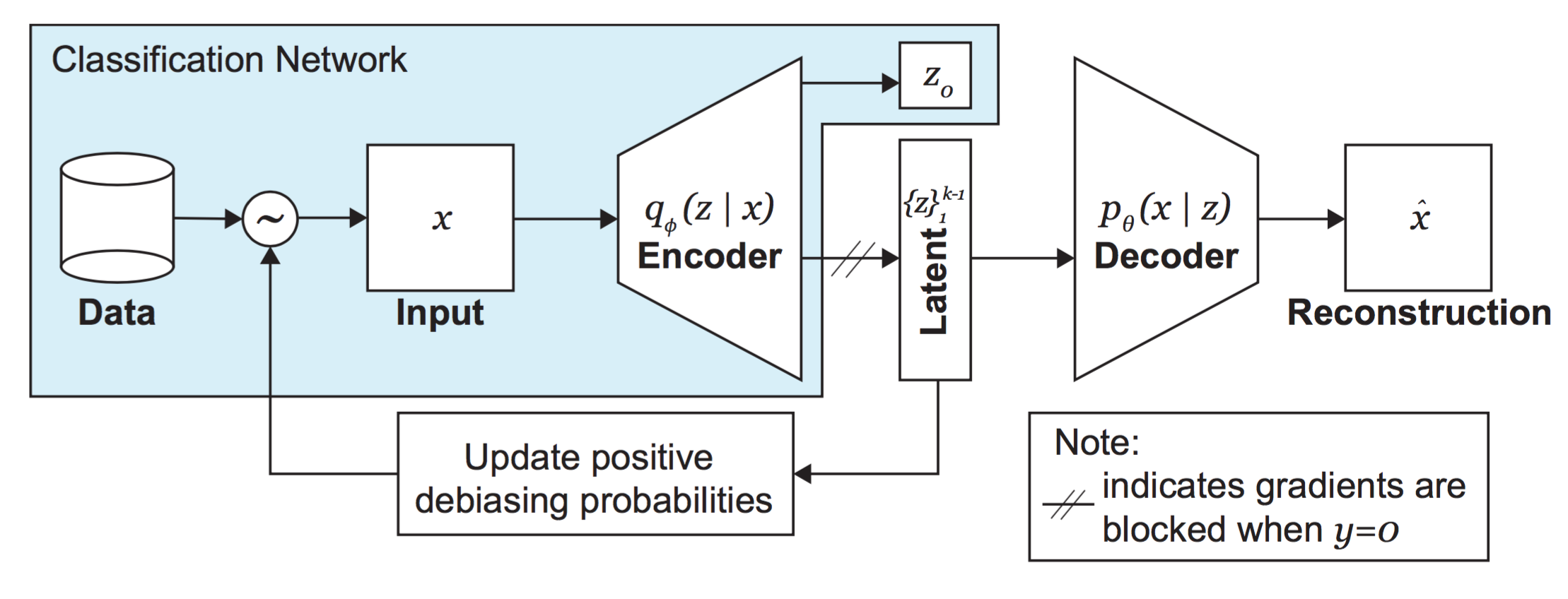
DB损失函数:
1 | # 输入:输入值,重构值,真正的标签值,预测的标签值,隐分布的均值,隐分布标准方差的log值 |
定义DBVAE的解码器部分:
1 | # 解码器部分 |
定义和创建DB—VAE网络:
1 | class DB_VAE(tf.keras.Model): |
实现DB-VAE
定义一个辅助函数,输出隐变量均值
1 | def get_latent_mu(images, dbvae, batch_size=1024): |
重新定义重采样算法:
1 | # 根据图像在训练数据中的分布重新计算批次中图像的采样概率的函数 |
训练DB-VAE网络:
1 | # Hyperparameters |
准确性评估:
1 | dbvae_logits = [dbvae.predict(np.array(x, dtype=np.float32)) for x in test_faces] |